I've watched a trading desk grow a "temporary" Excel workflow into a systemic risk.
It started small. OTC instruments, custom terms, manageable positions. Someone built a spreadsheet on their desktop. Then the volume grew. And grew. And grew some more.
By the time we arrived, that Excel file was running their entire risk management operation.
When I ask clients why they haven't replaced these systems, the answer is always the same: "It was built a long time ago. The guy who built it has left. We don't really know how it works."
You'd think the solution is simple. Just hook up an API. Integrate a proper risk system. Move on.
That's the lie the industry tells itself.
The Documentation Is "Mostly Accurate"
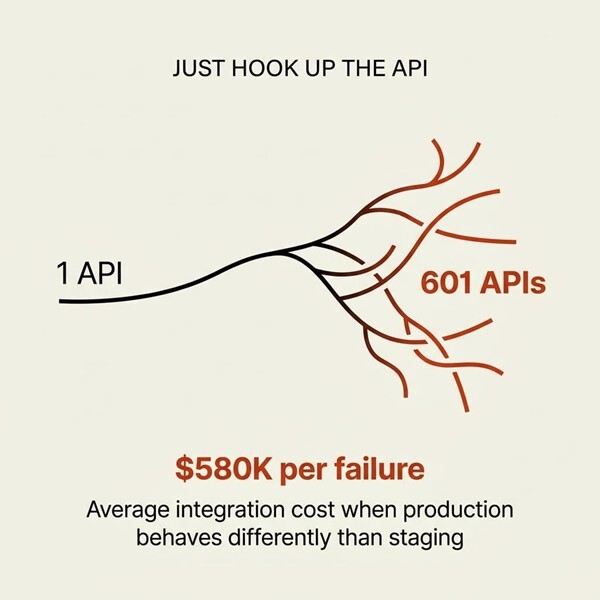
Financial institutions now manage an average of 601 APIs. That number grows every quarter as modernization efforts accelerate.
The promise is clean integration. Standard endpoints. Clear documentation.
The reality is messier.
I've seen a 2024 accounting API version update break 19% of connected applications when field structures changed. The documentation said it was backward compatible. The production environment disagreed.
Each of these updates hides in a changelog or YAML diff long before an outage surfaces. You discover the problem when your KYC pipeline stops working at 3am.
Legacy systems suffer from a lack of documentation, recycled reference data, and poor system hygiene. Staff turnover means institutional knowledge about custom-built systems walks out the door.
The Excel file nobody understands? At least it's visible. At least someone knows it exists.
The API integration that "just works" until it doesn't? That's the invisible systemic risk.
Production Behaves Differently Than Staging
We're working on an FX trading system for a broker client. The brief was simple: "We have nothing, so we're starting from scratch."
Greenfield. Clean slate. Perfect.
Except they did have something. It was just disconnected, disorganized, and unstructured.
Our challenge became figuring out which systems survive, which speak to each other, and which get turned off. That's not greenfield work. That's archaeology.
Capital markets face data fragmentation across order management, execution, risk engines, and post-trade platforms. This creates latency and operational risk where endpoints behaving differently in production becomes the norm, not the exception.
You build against staging. You test against staging. Everything passes.
Then you hit production and discover:
- Rate limits that weren't documented
- Timeout behaviors that differ from the spec
- Field validations that only trigger under load
- Caching layers that create stale data
The cost? API integration failures average $580,000 per incident. Downtime alone reaches $9,000 per minute.
"Just hook up the API" is an expensive misconception.
The Parallel Build Strategy
You can't replace a critical Excel system by turning it off and hoping the new one works.
I've learned to treat integration work as relationship management, not plumbing. You're not connecting pipes. You're negotiating between systems that were never designed to speak to each other.
The way to build new is to build in parallel.
Here's what that actually means:
First, disseminate the problem the solution purports to solve. I'm not in the business of building faster horses, to paraphrase Steve Jobs. I look at the business case and take a fresh look at whether the existing solution solves the problem in a good way, or if there is a better way.
More often than not, a fresh mind brings better solutions to the table.
Second, build to feature parity before cutover. Only when we've reached equivalent functionality do we turn off the old system and turn on the new. Sometimes you can manage a gradual transition, but not always.
Third, accept that reverse engineering is disruptive. A competent technologist could figure out what that Excel file does. But the process itself creates risk. You're touching a system the business depends on to understand their actual exposure.
The core issue isn't having the file broken. The core issue is that trading organizations relying on these tools to manage their risk could be misinformed as to what their actual exposure was, and therefore make irresponsible trading decisions.
That could ultimately affect both their organization's stability or have systemic impact.
The AI Productivity Trap
The new developers are those who are competent at prompt engineering.
But using AI and "vibe coding" isn't all about having non-engineers code away using AI-assisted IDEs. Yes, it's possible. But it leaves architecture, design, non-functional requirements, and other considerations we as computer scientists are acutely aware of by the wayside.
To deliver AI-assisted code requires a strong scaffold around architecture and boundaries for the AI. It requires the prompt engineer to understand the code and to be deliberate when defining approach and architecture.
The Pareto rule applies here too.
80% of the work happens with 20% of the effort. It's the last 20% that requires real effort.
It's easy to look super productive using AI. But use it badly, and getting past the last 20% will take forever.
I've seen teams generate thousands of lines of code in hours. The code compiles. The tests pass. It looks like magic.
Then you hit production and discover:
- No error handling for edge cases
- Race conditions under concurrent load
- Memory leaks that only appear after days of uptime
- Security vulnerabilities in authentication flows
The teams that get through that last 20% efficiently are the ones who use AI to accelerate implementation, not to replace understanding.
What Actually Works
I don't have a framework that makes integration simple. I have scar tissue from implementations that looked clean on paper and became nightmares in production.
What I've learned:
Treat every "greenfield" project as brownfield until proven otherwise. Ask what systems already exist. Ask what data flows already happen. Ask who depends on what.
Build in parallel until you reach feature parity. Don't turn off the old system until the new one can handle everything the business depends on.
Document what you discover, not what you assume. The gap between API documentation and production behavior is where incidents live.
Use AI to accelerate the 80%, but architect the 20%. Code generation is powerful. It's not a replacement for understanding systems, data flows, and failure modes.
Respect the Excel file. It survived this long for a reason. Your job isn't to mock it. Your job is to understand what problem it solves and build something better.
The Real Work
Integration isn't plumbing. It's negotiation between systems that were never designed to speak to each other, built by people who left years ago, documented in changelogs nobody reads.
The promise is: just hook up the API.
The reality is: figure out which systems survive, which speak to each other, and which get turned off. Build in parallel. Reach feature parity. Test under load. Document what actually happens in production, not what the spec says should happen.
That's the work.
It's not simple. It's not fast. It's not what the sales deck promised.
But it's what keeps trading desks from making irresponsible decisions based on misinformed risk exposure.
And that's worth doing right.